Веб-скрейпинг — это мощный инструмент для сбора данных с веб-сайтов. Тем не менее, многие веб-сайты используют службы безопасности, такие как Cloudflare, для защиты своего контента. Итак, как обойти Cloudflare при попытке парсинга данных? Cloudflare может блокировать попытки скрейпинга, обнаруживая подозрительную активность. Это создает серьезную проблему для тех, кто хочет собирать данные с этих сайтов. Чтобы обойти Cloudflare, вам нужны эффективные методы, которые позволят вам получить доступ к нужным данным без блокировки. Почему обход Cloudflare так важен для успешного веб-скрейпинга? Не обходя его, ваши попытки скрейпинга могут быть остановлены, что приведет к потере времени и ресурсов. Ключом к эффективному сбору данных является знание того, как обойти защиту Cloudflare. В этой статье мы покажем вам методы, которые вы можете использовать для обхода Cloudflare и успешного сбора данных.
Что такое управление ботами Cloudflare?
Облачная вспышкаиграет решающую роль в защите веб-сайтов от различных онлайн-угроз, таких как атаки и боты. Например, когда вы посещаете веб-сайт, такой как интернет-магазин, Cloudflare может работать за кулисами, чтобы гарантировать, что доступ к сайту имеют только реальные пользователи, а не боты.
Но когда дело доходит до веб-скрейпинга, Cloudflare может стать проблемой. Веб-сайты часто используют Cloudflare Bot Management для обнаружения и блокировки автоматизированных инструментов, которые собирают данные. Это делается путем анализа поведения посетителей, проверки IP-адресов и выявления подозрительных шаблонов. Например, если бот пытается собрать данные с веб-сайта слишком быстро или слишком часто, Cloudflare может заблокировать IP-адрес или бросить вызов боту с помощью CAPTCHA.
Итак, как обойти Cloudflare в таких случаях? Когда вы занимаетесь веб-скрейпингом, это может помешать вам получить доступ к нужным данным. Обход Cloudflare становится важным, потому что без него вы можете столкнуться с блокировками и задержками, что повлияет на эффективность вашего скрейпинга. Цель Cloudflare Bot Management — остановить эти попытки автоматического скрейпинга, но если вы знаете правильные методы, вы все равно можете обойти Cloudflare и продолжить сбор необходимых данных.
Как Cloudflare обнаруживает ботов?
Чтобы защитить веб-сайты от веб-скрейпинга, Cloudflare использует как пассивные, так и активные методы обнаружения ботов. Эти методы помогают Cloudflare анализировать посетителей и отделять людей от автоматизированных ботов. Давайте подробнее рассмотрим, как Cloudflare обнаруживает подозрительных ботов и как это влияет на вашу способность обходить Cloudflare для веб-скрейпинга.
Методы пассивного обнаружения
Cloudflare использует такие методы, какСнятие отпечатков пальцев TLSиЦифровые отпечатки по IPдля идентификации ботов. Например, когда бот пытается получить доступ к веб-сайту, он часто использует другой отпечаток TLS (Transport Layer Security), чем обычный браузер. Cloudflare может отслеживать это и помечать как подозрительное. Подобным образомЦифровые отпечатки по IPсмотрит на источник запроса. Если бот сканирует несколько веб-сайтов с одного и того же IP-адреса за короткое время, это вызывает тревогу. Еще один распространенный метод включает в себя проверкуHTTP-заголовки. Если заголовки кажутся несогласованными или в них отсутствует важная информация, Cloudflare может определить, что запрос поступает от бота.
Методы активного обнаружения
Cloudflare также используетЗадачи JavaScriptчтобы убедиться, что посетитель является человеком. Например, Cloudflare может потребовать от пользователя решить небольшую задачу JavaScript перед доступом к сайту. Ботам сложно пройти этот вызов, но человеку легко. ДополнительноАнализ поведенияСледит за тем, как пользователи взаимодействуют с сайтом. Если движение или щелчок кажутся роботизированными (например, запросы выполняются слишком быстро), Cloudflare пометит это. Наиболее распространенной активной техникой является методКАПЧАвызов. Cloudflare может отображать капчу, чтобы подтвердить, что посетитель является человеком, а не ботом, собирающим данные.
Для тех, кто пытается обойти Cloudflare, понимание этих методов обнаружения является ключевым. Чтобы продолжить веб-скрейпинг без перерывов, вам нужно знать, как избежать срабатывания этих пассивных и активных мер безопасности. Адаптируя свои методы скрейпинга, такие как ротация IP-адресов, использование правильных HTTP-заголовков или решение проблем JavaScript, вы можете обойти Cloudflare и получить доступ к нужным вам данным.
Методы обхода защиты Cloudflare
Теперь, когда мы понимаем, как Cloudflare обнаруживает ботов, давайте рассмотрим эффективные методыобход CloudflareЗащита и эффективный скрейпинг данных.
1. Использование решателей Cloudflare
Одним из популярных способов обойти безопасность Cloudflare является использование специализированныхРешатели CloudflareлюбитьФлэрсолверр. Эти инструменты предназначены для решения таких задач, как проверки JavaScript иКАПЧАПроверяет в автоматическом режиме. Например, FlareSolverr может взаимодействовать с задачами JavaScript Cloudflare и решать их, не требуя участия человека. Это позволяет вашему парсеру продолжать работу без перебоев, даже когда Cloudflare запрашивает CAPTCHA или проверку JavaScript. Использование этих решателей гарантирует, что ваши попытки скрейпинга обойдут защитные слои Cloudflare.
 2. Ротация IP-адресов
2. Ротация IP-адресов
Еще один важный способ обойти Cloudflare — вращениеIP-адреса. Cloudflare часто обнаруживает повторные попытки скрейпинга с одного и того же IP-адреса и может блокировать или ограничивать скорость этих запросов. Меняя IP-адреса, вы можете избежать обнаружения и обойти блокировки Cloudflare на основе IP-адресов. С помощью прокси-пулов илирезидентные прокси— отличный способ убедиться, что ваш парсер использует большое количество разнообразных IP-адресов. Резидентные прокси, например, помогают моделировать реальный пользовательский трафик, что затрудняет для Cloudflare идентификацию запроса как автоматического скрейпинга.
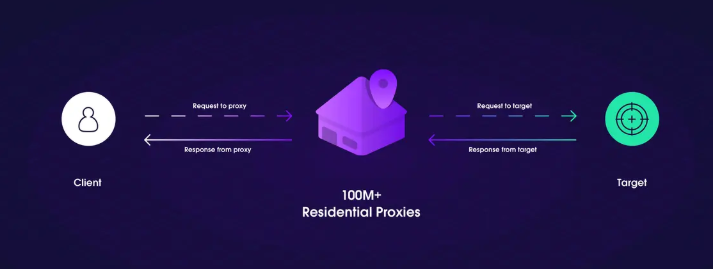 (источник:Оксилабы)
(источник:Оксилабы)
3. Моделирование поведения, подобного человеческому
Чтобы еще больше снизить уровень обнаружения, моделированиеЧеловекоподобное поведениеимеет важное значение. Это можно сделать с помощьюHeadless браузерыс функциями защиты от обнаружения, такими какКукловодилиДраматург. Эти инструменты позволяют программно управлять браузером и имитировать действия человека, такие как прокрутка, клики и ввод текста. Кроме того, сочетание этих инструментов сАнтидетектирующие плагинылюбитьpuppeteer-extra-plugin-stealthможет помочь обойти анализ поведения Cloudflare, который ищет роботизированные шаблоны во взаимодействии с пользователем. Этот метод очень эффективен для обхода как пассивных, так и активных методов обнаружения.
 (источник:Шаника Викрамасингхе)
(источник:Шаника Викрамасингхе)
4.Использование антидетект-браузеров
Для еще лучших результатов используйте антидетект-браузеры, такие какDICloakможет изменить правила игры. Эти браузеры предназначены для имитации реальной активности пользователя путем маскировки вашего цифрового отпечатка. Имитируя поведение легитимного пользователя, антидетект-браузеры могут избежать распространенныхПроблемыиПоведенческий анализметоды, используемые Cloudflare. Это позволяет вашим усилиям по веб-скрейпингу оставаться незамеченными и более эффективными. В дополнение к маскировке отпечатков пальцев, DICloak также предлагаетRPA (роботизированная автоматизация процессов)функции, которые позволяют вашему парсеру автоматизировать задачи и взаимодействовать с веб-сайтами как реальный пользователь. Это делает скрейпинг более динамичным и адаптируемым, что еще больше снижает риск обнаружения Cloudflare.
5. API веб-скрейпинга
Эффективный способобход CloudflareЗащита заключается в использованииAPI веб-скрейпинга. Эти API разработаны для того, чтобы справиться со сложными функциями безопасности Cloudflare за вас. НапримерScraperAPIилиЗайтможет управлять ротацией IP-адресов, обходить CAPTCHA и автоматически обрабатывать задачи JavaScript. Вместо того, чтобы разбираться с техническими деталями, вы можете просто отправлять запросы к API и получать нужные вам данные, в то время как он заботится об обходе Cloudflare за вас. Такой метод экономит время и обеспечивает более плавное соскабливание.
Пример кода (ScraperAPI):
import requests
# Using ScraperAPI to request a webpage
url = "https://example.com"
api_key = "your_scraperapi_key"
response = requests.get(f"http://api.scraperapi.com?api_key={api_key}&url={url}")
# Get the response content
print(response.text)
6. Обходите Cloudflare CDN, обращаясь к серверу-источнику
Еще один методобход Cloudflareзаключается в том, чтобы вызвать методИсходный серверпрямо. Cloudflare выступает в качестве прокси-сервера, поэтому доступ к сайту через CDN Cloudflare может вызвать проблемы с безопасностью. Однако, определив и обратившись непосредственно к исходному серверу (т. е. к серверу, на котором размещен фактический контент сайта), вы можете обойти защиту Cloudflare.
Для этого вам, возможно, потребуется открыть для себяIP-адрес исходного сервера, которые иногда могут быть обнаружены через утечки DNS или предыдущие записи. Как только у вас есть IP-адрес исходного сервера, вы можете отправлять запросы непосредственно к нему, избегая уровня CDN Cloudflare.
Пример кода (Получить IP-адрес сервера Origin):
import socket
# Get the IP address of the target domain (sometimes the origin server's IP)
hostname = "example.com"
ip_address = socket.gethostbyname(hostname)
print("Origin Server IP:", ip_address)
7. Обходите зал ожидания Cloudflare и реконструируйте его задачу
В Cloudflare есть функция под названиемзал ожидания, часто наблюдается во время мероприятий с интенсивным движением. Эта функция может задерживать пользователей и бросать им вызов с помощью таких задач, как CAPTCHA. Комуобход зала ожидания Cloudflare, вам нужно реконструировать, как это работает.
Один из методов — проанализировать запросы, сделанные при входе в зал ожидания, изучить, как запускается челлендж, и автоматизировать взаимодействие с ним. Такие инструменты, какСкрипачилиЛюкс для отрыжкиможет помочь проверить сетевой трафик и понять, как работает задача Cloudflare. После того, как вы реконструируете задачу, вы можете автоматизировать ее, чтобы не ждать загрузки страницы.
Пример кода (Автоматизация взаимодействия с Selenium):
from selenium import webdriver
from selenium.webdriver.common.by import By
# Using Selenium to load the page and wait for the challenge
driver = webdriver.Chrome(executable_path="path_to_chromedriver")
# Visit the target site
driver.get("https://example.com")
# Wait for and handle Cloudflare's JavaScript challenge
driver.implicitly_wait(10) # Wait for the page to load
driver.find_element(By.CSS_SELECTOR, "button#submit").click() # Automatically click the submit button (if any)
# Get the page content
page_content = driver.page_source
print(page_content)
# Close the browser
driver.quit()
8. Обход капчи Cloudflare
Распространенная проблема при скрейпингеЗащита от Cloudflareсайтов сталкивается сКАПЧАПроблемы. Чтобы обойти Cloudflare CAPTCHA, вы можете использовать сервисы решения CAPTCHA, такие как2КапчаилиАнтикапча, которые используют реальных людей или искусственный интеллект для решения CAPTCHA за вас. Эти сервисы могут интегрироваться с вашим скрейпером и автоматически обходить подсказки CAPTCHA, что позволит вам беспрепятственно продолжить работу по скрейпингу.
Однако, чтобы этот метод работал без проблем, вы должны сочетать его сМетоды защиты от обнаружениянапример, ротация IP-адресов и использование инструментов автоматизации браузера, таких какКукловодчтобы ваша активность была похожей на человеческую.
Пример кода (использование 2Captcha для расчета CAPTCHA):
import requests
# 2Captcha API key
api_key = "your_2captcha_api_key"
site_key = "site_key_of_the_target_page"
url = "https://example.com/captcha_page"
# Request CAPTCHA challenge
captcha_response = requests.post("http://2captcha.com/in.php", data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': url,
}).json()
captcha_id = captcha_response['request']
# Get the solved CAPTCHA result
captcha_result = requests.get(f"http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}").json()
# CAPTCHA solution
captcha_solution = captcha_result['request']
# Submit the solution to the target page
response = requests.get(f"{url}?g-recaptcha-response={captcha_solution}")
print(response.text)
9. Очистите кэш Google
Если сайт надежно защищен Cloudflare, вы иногда можете обойти его безопасность, очищая кэш Google. Google часто кэширует версии веб-страниц, к которым можно получить доступ, не вызывая проблем Cloudflare.
Выполнив поиск по URL-адресу вГуглЩелкнув по кэшированной ссылке, вы можете извлечь контент из кэшированной версии, а не из действующего сайта. Этот метод не всегда работает, если кэш устарел, но это полезный обходной путь при работе с сайтами, которые имеют сильную **защиту Cloudflare**.
Пример кода (доступ к кэшу Google):
import requests
# Get Google cache URL
url = "https://www.example.com"
cache_url = f"http://webcache.googleusercontent.com/search?q=cache:{url}"
# Request the cached page
response = requests.get(cache_url)
# Get the cached page content
print(response.text)
Заключение
Успешное обходЗащита от Cloudflareимеет важное значение для эффективной работыВеб-скрейпинг. С помощью таких методов, какAPI для скрейпинга, ротация IP-адресов, решениеКАПЧА, моделирование человеческого поведения и реверс-инжиниринг таких задач, какЗалы ожидания, вы можете преодолеть барьеры, которые устанавливает Cloudflare. Каждый метод предоставляет решение для различных аспектов мер безопасности Cloudflare, позволяя вам плавно собирать данные без блокировки. Тем не менее, всегда следите за тем, чтобы ваша деятельность по скрейпингу была этичной и соответствовала соответствующим законам.
 Бесплатные инструменты
Бесплатные инструменты Плагин Cookie
Плагин Cookie Генератор UA
Генератор UA Генератор MAC-адресов
Генератор MAC-адресов Генератор IP-адресов
Генератор IP-адресов Список IP-адресов
Список IP-адресов Генератор кода 2FA
Генератор кода 2FA Мировые Часы
Мировые Часы Проверка анонимности
Проверка анонимности WebRTC Leak Test
WebRTC Leak Test Генератор UUID
Генератор UUID Проверка прокси
Проверка прокси Проверка FB Рекламы
Проверка FB Рекламы AI-веб-скрейпинг
AI-веб-скрейпинг Бесплатные SMM-инструменты
Бесплатные SMM-инструменты Проверщик теневой блокировки Twitter
Проверщик теневой блокировки Twitter Проверка имени в Instagram
Проверка имени в Instagram UTM-генератор
UTM-генератор Генератор username
Генератор username AI генератор хэштегов
AI генератор хэштегов Генератор заголовков LinkedIn
Генератор заголовков LinkedIn Размер изображений для соцсетей
Размер изображений для соцсетей