Вы когда-нибудь хотели собрать информацию с Reddit для исследований, анализа рынка или создания контента? Вы не одиноки! Как человек, который провел годы, работая с инструментами извлечения данных, я обнаружил, что Reddit — это кладезь инсайтов, если вы знаете, как правильно к нему получить доступ.
В этом исчерпывающем руководстве я расскажу вам все, что нужно знать о скрейперах Reddit: что это такое, как они работают, какие инструменты лучше всего подходят как для новичков, так и для профессионалов, и как использовать их этично и законно. Я даже поделюсь некоторыми личными опытом и советами, которые я узнал на этом пути.
Что можно извлечь из Reddit?
Прежде чем погрузиться в инструменты и техники, давайте рассмотрим, какие данные вы можете фактически извлечь из Reddit. Эта платформа предлагает огромное количество информации в тысячах сообществ (сабреддитов), что делает ее неоценимой для исследователей, маркетологов и создателей контента.

Посты и темы
Наиболее распространенными целями для скрейпинга Reddit являются посты и связанные с ними темы. Когда я впервые начал скрейпить Reddit для проекта по исследованию рынка, я был поражен тем, сколько потребительских инсайтов скрыто на виду. Вы можете извлечь:
•Заголовки и содержание постов
•Количество голосов "за" и "против"
•Даты и время публикации
•Темы комментариев и вложенные ответы
•Награды и специальные признания
Например, когда я скрейпил r/TechSupport для клиента, мы обнаружили повторяющиеся проблемы с продуктом, которые не отображались в их заявках в службу поддержки. Этот инсайт помог им решить проблему до того, как она стала PR-кошмаром!
Информация о сабреддите
Каждый сабреддит — это сообщество с собственной культурой и фокусом. Скрейпинг данных сабреддита может раскрыть:
•Количество подписчиков и тенденции роста
•Правила и рекомендации сообщества
•Шаблоны публикаций и пики активности
•Информация о модераторах
•Связанные сабреддиты
Однажды я использовал этот подход, чтобы помочь игровой компании определить, какие сабреддиты будут наиболее восприимчивы к их новому релизу, основываясь на размере сообщества и паттернах вовлеченности с похожими играми.
Профили пользователей
Данные пользователей могут предоставить ценные сведения о паттернах поведения и предпочтениях:
•История публикаций и комментариев
•Счета кармы
•Возраст аккаунта
•Активные сообщества
•История наград
Помните, что хотя эти данные доступны публично, важно уважать конфиденциальность и анонимизировать любые данные, которые вы собираете для анализа или отчетности.
Сравнение лучших инструментов для скрапинга Reddit
После тестирования десятков инструментов за эти годы, я сузил выбор до самых эффективных скрапов Reddit, доступных в 2025 году. Давайте сравним их по удобству использования, функциям и стоимости.
Плюсы:
•Бесплатный и с открытым исходным кодом
•Всеобъемлющий доступ к API Reddit
•Отличная документация и поддержка сообщества
•Автоматически обрабатывает ограничения по скорости
•Высокая настраиваемость под конкретные нужды
Минусы:
•Требует знаний Python
•Процесс настройки включает создание аккаунта разработчика Reddit
•Ограничен правилами API Reddit
Лучше всего для: Разработчиков и специалистов по данным, которые уверенно работают с кодом и нуждаются в настраиваемых решениях.
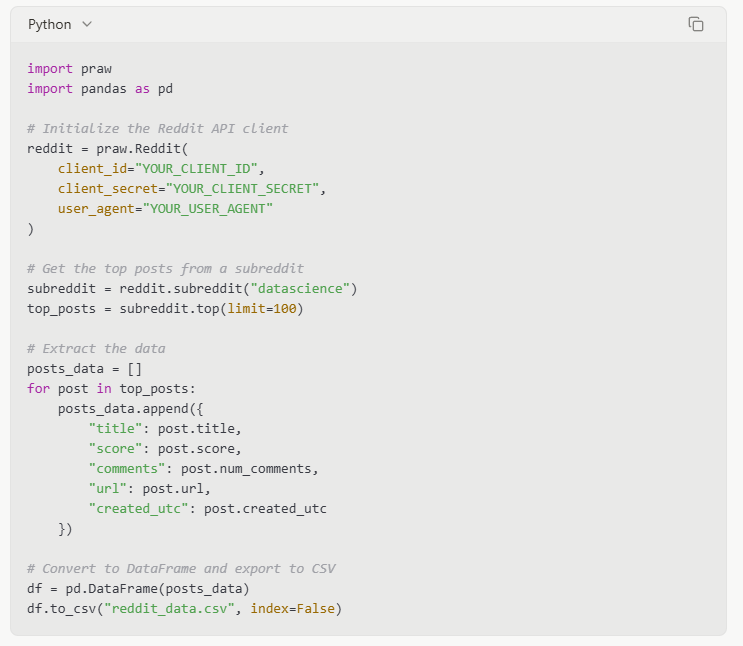
Я использовал PRAW для нескольких крупных исследовательских проектов, и его надежность не имеет себе равных. Кривая обучения того стоила, учитывая контроль, который он дал мне над тем, какие данные извлекать и как их обрабатывать.
Пример кода:
•Не требуется программирование — полностью визуальный интерфейс
•Автоматически обрабатывает загрузку динамического контента
•Облачные варианты выполнения
•Запланированный сбор данных через регулярные интервалы
•Несколько форматов экспорта (CSV, Excel, JSON)
•Бесплатная версия имеет ограничения по количеству записей
•Платные планы начинаются от $75 в месяц
•Кривая обучения для сложных задач по сбору данных
•Могут потребоваться корректировки по мере изменения макета Reddit
Лучше всего для: Бизнес-пользователей и исследователей без опыта программирования, которым необходимо регулярное извлечение данных.
Octoparse спас меня, когда мне нужно было выполнить проект анализа Reddit, но у меня не было времени писать собственный код. Визуальный интерфейс упростил выбор именно тех данных, которые мне нужны, а облачное выполнение позволило мне настроить и забыть об этом.
Apify Reddit Scraper
•Готовое решение специально для Reddit
•Не требуется аутентификация
•Удобный интерфейс с минимальной настройкой
•Обрабатывает постраничный вывод и потоки комментариев
•Надежные варианты экспорта
•Цены на основе использования могут увеличиваться для крупных проектов
•Менее настраиваемый, чем решения на основе кода
•Периодические задержки с очень новым контентом
Лучше всего для: Маркетологов и исследователей, которым нужны быстрые результаты без технической настройки.
Когда я работал с маркетинговой командой, которой срочно нужны были данные с Reddit, Apify стал моим основным инструментом. Мы смогли извлечь данные о настроениях из сабреддитов, связанных с продуктами, менее чем за час, что заняло бы дни, если бы писать код с нуля.
• Специализирован для структуры Reddit
• Не требуется вход для базового скрапинга
• Возможности пакетной обработки
• Хороший баланс удобства и функций
• Доступные ценовые категории
• Новый инструмент с меньшим сообществом
• Документация могла бы быть более полной
• Некоторые продвинутые функции требуют платной подписки
Лучше всего для: Малых предприятий и индивидуальных исследователей, которым нужны регулярные данные с Reddit без технической сложности.
Я начал использовать Scrupp в прошлом году для личного проекта по отслеживанию игровых трендов, и я был впечатлён тем, как он справляется со вложенной структурой комментариев Reddit — с чем многие скраперы сталкиваются с трудностями.

• Обрабатывает контент, рендерящийся с помощью JavaScript
• Может имитировать взаимодействия пользователя
• Хорошо работает с бесконечной прокруткой Reddit
• Высокая настраиваемость
• Требует знаний программирования
• Более ресурсоёмкий, чем решения на основе API
• Нуждается в регулярном обслуживании по мере изменения сайтов
Лучше всего для: Разработчиков, которым нужно скрапить контент, который не легко доступен через API.
Когда мне нужно было скрапить сабреддит, который использовал пользовательские виджеты и бесконечную прокрутку, Selenium был единственным инструментом, который мог надёжно захватить всё. Настройка требует больше усилий, но он может справиться почти с любой задачей по скрапингу.
Решения без кода для скрапинга Reddit
Не у всех есть время или технические навыки для написания кода для извлечения данных. К счастью, появилось несколько инструментов без кода, которые делают парсинг Reddit доступным для всех.
Пошаговое руководство по Octoparse
Позвольте мне показать вам, как я использовал Octoparse для парсинга сабреддита, не написав ни строчки кода:
1. Скачайте и установите Octoparse с их официального сайта
2. Создайте новую задачу, нажав кнопку "+"
3. Введите URL Reddit, который вы хотите парсить (например, https://www.reddit.com/r/datascience/)
4. Используйте интерфейс "указатель и клик", чтобы выбрать элементы, которые вы хотите извлечь:
• Нажмите на заголовок поста, чтобы выбрать все заголовки
• Нажмите на количество голосов "за", чтобы выбрать все подсчеты
• Нажмите на имена пользователей, чтобы выбрать всех авторов
5. Настройте пагинацию, указав Octoparse нажимать кнопку "Далее" или прокручивать вниз
6. Запустите задачу либо на вашем локальном компьютере, либо в облаке
7. Экспортируйте данные в формате CSV, Excel или JSON
В первый раз, когда я использовал этот подход, я смог извлечь более 500 постов из r/TechGadgets за примерно 20 минут, включая заголовки, оценки и количество комментариев — все это без написания кода!
Другие варианты без кода
Если Octoparse не соответствует вашим потребностям, рассмотрите эти альтернативы:
• ParseHub: Отлично подходит для сложных веб-сайтов с щедрым бесплатным тарифом
• Import.io: Ориентирован на предприятия с мощными инструментами трансформации
• Webscraper.io: Расширение для браузера для быстрых и простых задач парсинга
Я обнаружил, что у каждого из них есть свои сильные стороны, но Octoparse предлагает наилучший баланс мощности и удобства использования именно для Reddit.
Законно ли парсить Reddit?
Это, возможно, самый распространенный вопрос, который я слышу, и ответ не черно-белый. На основе моего исследования и опыта, вот что вам нужно знать:
Правовая ситуация
Сам по себе веб-парсинг не является незаконным, но то, как вы это делаете и что вы делаете с данными, имеет огромное значение. Когда дело касается Reddit:
1. Условия обслуживания Reddit позволяют "личное, некоммерческое использование" их услуг
2. Закон о компьютерном мошенничестве и злоупотреблениях (CFAA) был интерпретирован по-разному в различных судебных делах, касающихся веб-скрейпинга
3. Дело hiQ Labs против LinkedIn установило некоторый прецедент, что скрейпинг общедоступных данных может быть законным
На моем опыте, большинство юридических проблем возникает не из-за самого акта скрейпинга, а из-за того, как данные используются впоследствии.
Этические соображения
Помимо законности, существуют важные этические соображения:
• Уважайте robots.txt: файл robots.txt Reddit предоставляет рекомендации для автоматизированного доступа
• Ограничение частоты: чрезмерные запросы могут перегружать серверы Reddit
• Проблемы конфиденциальности: даже если данные являются общедоступными, пользователи могут не ожидать, что они будут собираться массово
• Атрибуция: если вы публикуете выводы, правильно указывайте Reddit и его пользователей
Я всегда советую клиентам анонимизировать данные при представлении результатов и быть прозрачными в отношении методов сбора данных.
Лучшие практики для соблюдения законодательства
Чтобы оставаться на безопасной стороне:
1. Читайте и уважайте Условия обслуживания Reddit
2. Реализуйте ограничение частоты в ваших инструментах скрейпинга
3. Не скрейпите частные сабреддиты или контент, требующий входа в систему
4. Анонимизируйте пользовательские данные в вашем анализе и отчетах
5. Используйте официальный API, когда это возможно
6. Учитывайте цель вашего сбора данных
Однажды я консультировал компанию, которая хотела скрейпить Reddit для получения отзывов о продуктах. Мы решили использовать официальный API с правильной атрибуцией и даже связались с модераторами соответствующих сабреддитов, чтобы обеспечить прозрачность. Этот подход не только позволил нам соблюдать закон, но и создал добрую волю с сообществами, которые мы изучали.
Обход мер против скрейпинга
Reddit, как и многие платформы, реализует меры для предотвращения чрезмерного скрейпинга. Вот как ответственно справляться с этими вызовами:
Распространенные механизмы против скрейпинга
За годы веб-скрапинга я столкнулся с несколькими техниками противодействия скрапингу на Reddit:
1. Ограничение частоты: ограничение количества запросов с одного IP
2. CAPTCHA: проверка автоматизированных инструментов с помощью тестов на верификацию
3. Блокировка IP: временная или постоянная блокировка подозрительных IP
4. Обнаружение User-Agent: идентификация и блокировка инструментов скрапинга
5. Динамическая загрузка контента: усложнение доступа к контенту программным способом
Ответственные стратегии обхода
Хотя я не призываю к агрессивному обходу, эти подходы могут помочь вам скрапить ответственно:
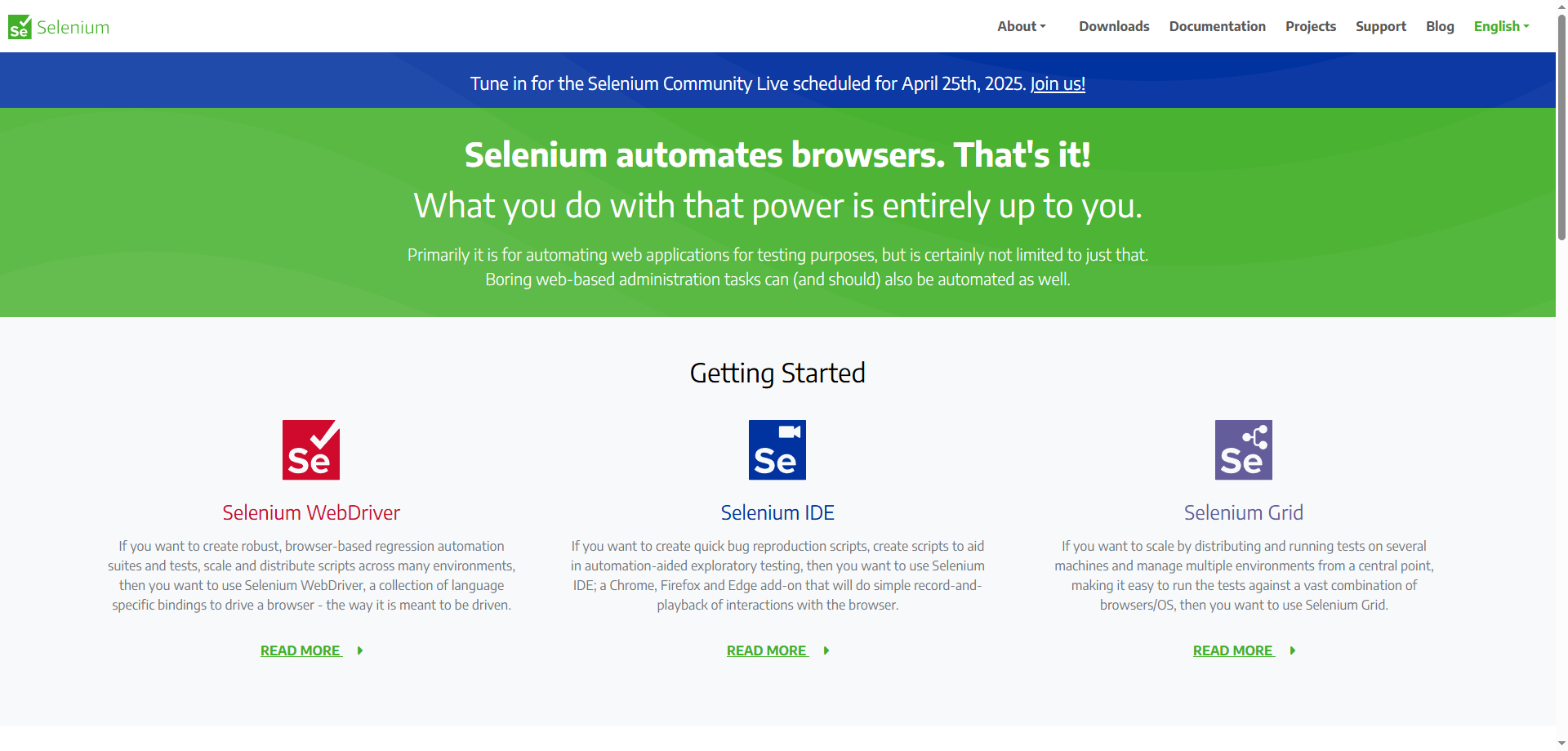
Ротация прокси
Использование нескольких IP-адресов через прокси может помочь распределить запросы и избежать срабатывания ограничений по частоте. Обычно я использую пул из 5-10 прокси для умеренных проектов по скрапингу, меняя их для каждого запроса.
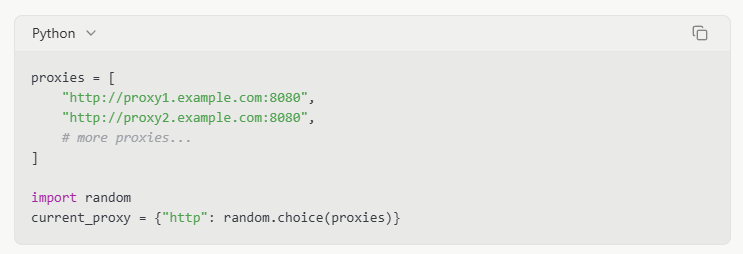
Управление заголовками запросов
Установка реалистичных заголовков браузера может помочь вашему скраперу слиться с обычным трафиком:
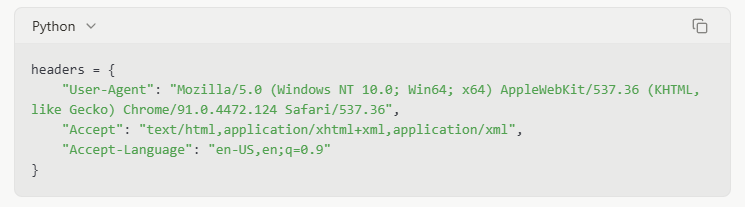
Уважительное время
Добавление задержек между запросами имитирует человеческие паттерны просмотра и снижает нагрузку на сервер:
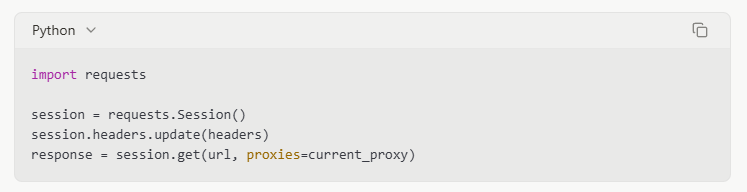
Управление сессиями
Сохранение cookies и информации о сессии может сделать запросы более легитимными:
Экспорт и использование данных Reddit
После успешного скрапинга Reddit следующим шагом является организация и экспорт этих данных в удобном формате.
Экспорт в CSV
CSV (значения, разделенные запятыми) идеально подходит для табличных данных и совместимости с программами для работы с электронными таблицами:

Я предпочитаю CSV для большинства проектов, потому что его легко открыть в Excel или Google Sheets для быстрого анализа или обмена с не техническими членами команды.
Экспорт в JSON
JSON (JavaScript Object Notation) лучше подходит для сохранения вложенных структур данных, таких как потоки комментариев:
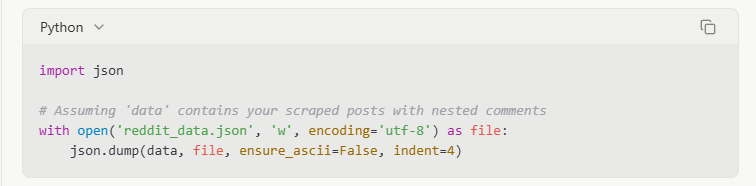
Когда я собирал данные с сабреддита с активными обсуждениями, JSON был необходим для поддержания родительских и дочерних отношений в потоках комментариев, которые были бы упрощены в формате CSV.
DataFrames Pandas
Для анализа данных в Python преобразование в DataFrame Pandas предлагает мощные возможности обработки:

Я нашел этот подход особенно полезным для проектов, требующих визуализации данных или статистического анализа, так как Pandas хорошо интегрируется с такими инструментами, как Matplotlib и Seaborn.
Расширенный сбор данных с Reddit с помощью автоматизации RPA от DICloak
Хотя инструменты, о которых мы говорили до сих пор, хорошо работают во многих сценариях, есть ситуации, когда вам нужны более сложные решения — особенно при работе с все более сложными мерами против ботов на Reddit или при управлении несколькими проектами по сбору данных одновременно.
Здесь на помощь приходит DICloak'Antidetect Browser с возможностями RPA (роботизированная автоматизация процессов). Я открыл этот инструмент в прошлом году, и он полностью изменил мой подход к сложным проектам по сбору данных.
Что отличает DICloak для сбора данных с Reddit
DICloak в первую очередь известен как антидетект браузер для управления несколькими аккаунтами, но его функциональность RPA делает его исключительно мощным для скрапинга Reddit:
1. Управление отпечатками браузера: DICloak создает уникальные, стабильные отпечатки браузера, которые помогают избежать сложных систем обнаружения Reddit.
2. Автоматизированные рабочие процессы: Функция RPA позволяет создавать пользовательские рабочие процессы для скрапинга, которые могут выполняться по расписанию.
3. Поддержка нескольких аккаунтов: Идеально, если вам нужно получить доступ к различным аккаунтам Reddit для различных проектов скрапинга.
4. Интеграция прокси: Бесперебойно работает с прокси для распределения запросов.
5. Визуальный конструктор рабочих процессов: Создавайте последовательности скрапинга без программирования.
Если вы заинтересованы в настройке пользовательских рабочих процессов RPA для скрапинга Reddit, вы можете обратиться в службу поддержки DICloak, чтобы обсудить ваши конкретные требования. Они предлагают персонализированную помощь в создании эффективных решений для скрапинга, которые учитывают как технические ограничения Reddit, так и условия обслуживания.
Заключение
Скрапинг Reddit предлагает невероятные возможности для исследователей, маркетологов и любителей данных, чтобы получить доступ к одному из самых богатых источников контента, созданного пользователями, и обсуждений в интернете. В этом руководстве мы рассмотрели различные инструменты и техники, доступные от кодовых решений, таких как PRAW, до безкодовых опций, таких как Octoparse, а также продвинутые подходы с использованием автоматизации RPA от DICloak.
Основные выводы из моего многолетнего опыта скрапинга Reddit:
1. Выберите правильный инструмент в зависимости от вашего уровня навыков и потребностей.
2. Всегда скрапьте ответственно и этично.
3. Учитывайте юридические аспекты и условия обслуживания Reddit.
4. Реализуйте правильное ограничение скорости и ротацию прокси.
5. Обрабатывайте и экспортируйте ваши данные в форматах, которые соответствуют вашим целям анализа.
Независимо от того, проводите ли вы академическое исследование, собираете рыночные данные или отслеживаете тренды, подходы, изложенные в этом руководстве, помогут вам эффективно и ответственно извлекать ценные данные из Reddit.
Помните, что ландшафт веб-скрейпинга постоянно меняется, платформы регулярно обновляют свои структуры и защитные меры. Будьте в курсе изменений на платформе Reddit и соответственно корректируйте свои стратегии скрейпинга.
Вы пробовали какие-либо из этих методов скрейпинга Reddit? Мне было бы интересно узнать о вашем опыте и любых советах, которые вы могли бы обнаружить на этом пути!
Часто задаваемые вопросы
Нарушает ли это правила Reddit, если я скрейплю их сайт?
Соглашение пользователя Reddit не запрещает скрейпинг явно, но ограничивает автоматические запросы и требует соблюдения robots.txt. Для масштабного скрейпинга рекомендуется использовать официальный API, когда это возможно.
Как мне избежать блокировки при скрейпинге Reddit?
Реализуйте уважительные практики скрейпинга: используйте задержки между запросами, меняйте IP-адреса через прокси, устанавливайте реалистичные пользовательские агенты и ограничивайте объем и частоту вашего скрейпинга.
В чем разница между использованием API Reddit и веб-скрейпингом?
API предоставляет структурированные данные с явным разрешением, но имеет ограничения по скорости и требует аутентификации. Веб-скрейпинг может получить доступ к контенту, недоступному через API, но несет больше юридических и этических соображений.
Могу ли я продавать данные, которые я скрейплю из Reddit?
Продавать сырые данные, полученные с помощью скрейпинга из Reddit, обычно не рекомендуется и может нарушать их условия обслуживания. Однако продажа инсайтов и анализа, полученных из этих данных, может быть приемлема в некоторых контекстах.
Как мне скрейпить комментарии Reddit, которые загружаются динамически?
Для динамически загружаемых комментариев такие инструменты, как Selenium или автоматизация RPA от DICloak, могут имитировать прокрутку и нажатие кнопок "загрузить больше комментариев", чтобы получить доступ к вложенному или пагинированному контенту.
Какой лучший формат для хранения данных Reddit для анализа?
Для простых табличных данных хорошо подходит CSV. Для сохранения вложенных структур, таких как потоки комментариев, лучше использовать JSON. Для немедленного анализа в Python наиболее гибкими являются DataFrame библиотеки Pandas.
 Бесплатные инструменты
Бесплатные инструменты Плагин Cookie
Плагин Cookie Генератор UA
Генератор UA Генератор MAC-адресов
Генератор MAC-адресов Генератор IP-адресов
Генератор IP-адресов Список IP-адресов
Список IP-адресов Генератор кода 2FA
Генератор кода 2FA Мировые Часы
Мировые Часы Проверка анонимности
Проверка анонимности WebRTC Leak Test
WebRTC Leak Test Генератор UUID
Генератор UUID Проверка прокси
Проверка прокси Проверка FB Рекламы
Проверка FB Рекламы AI-веб-скрейпинг
AI-веб-скрейпинг Бесплатные SMM-инструменты
Бесплатные SMM-инструменты Проверщик теневой блокировки Twitter
Проверщик теневой блокировки Twitter Проверка имени в Instagram
Проверка имени в Instagram UTM-генератор
UTM-генератор Генератор username
Генератор username AI генератор хэштегов
AI генератор хэштегов Генератор заголовков LinkedIn
Генератор заголовков LinkedIn Размер изображений для соцсетей
Размер изображений для соцсетей